现有的业务系统数据通常存储在数据库中,而AI大模型本身并不具备直接访问数据库的能力。因此,需要通过接口将数据库中的数据查询出来,再传递给大模型进行进一步分析与处理。由于人类语言对数据需求的表达较为随意,首先需要将用户的意图转换为合适的SQL查询语句,并通过接口执行查询操作。查询结果返回后,AI大模型会根据需求进行处理,并以友好的方式输出结果。
然而,查询返回的数据量可能过多,导致大语言模型截断部分数据,或在处理过程中出现错误。为此,本文提出了一种两种情境的处理方案:
- 当数据量过多时,程序直接输出数据,避免大语言模型处理的复杂性。
- 当数据量较少时,交由大语言模型进行友好的数据输出。
基于Dify平台实现这一流程的具体步骤如下:
- 分析用户需求并转换为SQL语句
使用大语言模型(LLM)分析用户的查询需求,并将其转化为有效的SQL查询语句。 - 调用系统接口执行SQL查询
通过系统接口执行SQL查询,获取相应的数据库数据。 - 分析数据量并决定输出方式
使用LLM对查询结果的数据量进行分析。若数据量大于8条,直接输出数据;若数据量小于等于8条,则由大语言模型进行友好的输出。 - 处理结构化数据并输出
对于查询结果大于8条的情况,使用Python程序对结构化数据进行处理,将数据库中的字段转化为易于理解的形式,并直接输出结果。 - 使用LLM输出友好结果
对于查询结果小于等于8条的情况,使用LLM对数据进行进一步处理,将结果转化为人类易于理解的格式,最终输出给用户。
通过这种方式,可以有效提升数据查询与智能问答的体验,确保系统的灵活性和用户体验的友好性。
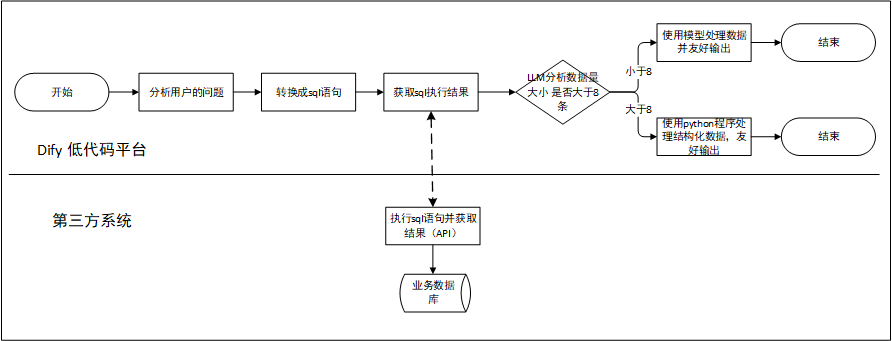
整体思路如下:
这里要说明的是,使用任何低代码平台的时候需要清晰的了解到每个低代码平台的能力边界是什么,要清晰的认识到它能做什么不能做什么,不要对它抱有太高的期望,也不要轻视它,需要仔细的评估它,让它成为合适工具。
在实际开发过程中有些开发者接触到一个新的开发平台,往往对这个开发平台寄予太高的期望,一旦平台的功能达不到开发者的期望这些开发者往往直接给这个平台冠以“不行”的名号。
在这个案例中,dify平台擅长的是快速构建一个操作流程,快速的引入大模型的能力,方便的调用第三方接口以及方便的以API、页面、切入式等方式发布。DIfy平台的不足(或者说平台设计之初根本不考虑,这不是贬义)结构化数据持久化存储,对文件的操作等这类场景。为此,我们就明确了我们和Dify平台的边界在哪里,那就就是使用DIfy平台快速构建流程,而我们来解决业务数据查询和持久化存储。各做个的,之间的交互用API接口处理。
由于业务数据完全存储在业务系统中,完全没有必要将业务数据迁移到Dify平台上,只需要通过接口获取业务系统中的数据即可。
dify整体流程如下:

这个流程中包含了以下几个关键环节。分别是LLM分析语义转SQL、HTTP 请求API接口、LLM分析API返回数据、LLM处理数据自然表达、代码执行格式化输出数据。
LLM分析语义转SQL:用于分析用户的自然语言,然后将其转成sql
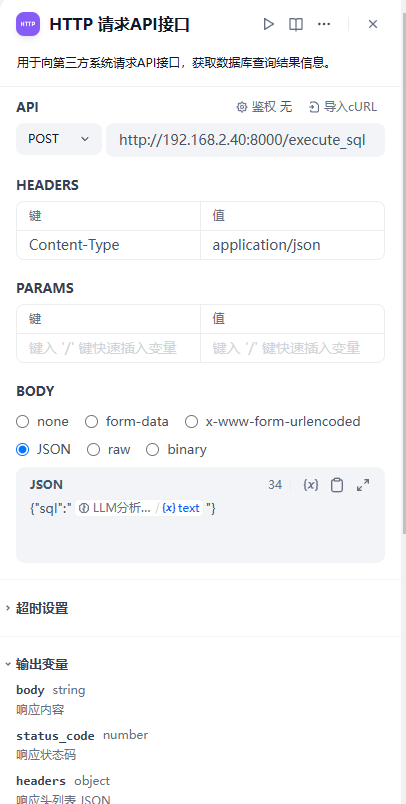
HTTP 请求API接口:用于向第三方系统请求API接口,获取数据库查询结果信息。
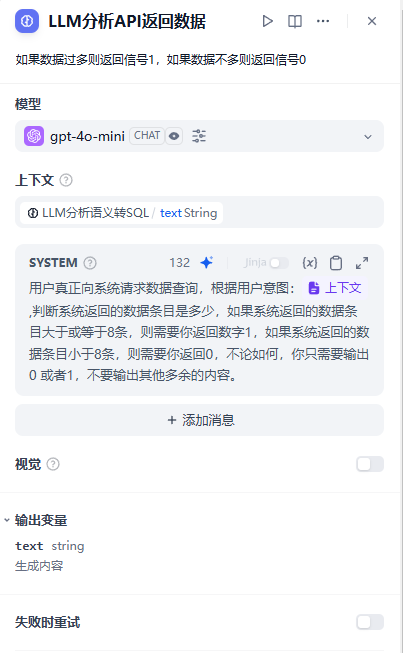
LLM分析API返回数据:如果数据过多则返回信号1,如果数据不多则返回信号0
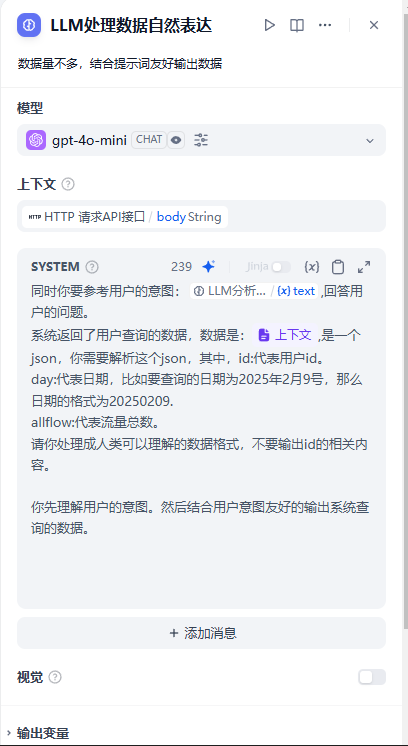
LLM处理数据自然表达:数据量不多,结合提示词友好输出数据
代码执行格式化输出数据:数据量大使用python脚本处理数据,格式化输出
LLM分析语义转SQL环节需要告诉大模型它的主要工作,告诉他数据库表和字段信息,好让它帮我们组合sql语句。例如下面的实例:
你是一个生成sql语句的助手,能够生成sqlite数据库的查询语句,你只需要按照要求生成sql语句,你的输只能是sql语句,不要输出其他任何多余的数据。你要查询数据库表,表名称是:flowinfo,表中包含三个字段,第一个字段是id,第二个字段是day,第三个字段是allflow。select 语句中必须包含表中的所有列。
id:代表用户id。
day:代表日期,比如要查询的日期为2025年2月9号,那么日期的格式为20250209.
allflow:代表流量总数。
三个字段都是数值类型。
以下是数据库中的一段数据:
id day all_flow
4588 20250209 826432
4586 20250208 843026
4584 20250207 787592
4583 20250206 752346
4582 20250205 746570
4581 20250204 928585
4574 20250203 767558
4573 20250202 773480
4565 20250201 679642
4564 20250131 567156
4571 20250130 596954
4566 20250129 495888
4568 20250128 445662
4567 20250127 553001
4541 20250126 418436
4538 20250125 421731
4543 20250124 501076
4559 20250123 632905
以下是你的工作流程:<userinput>代表用户输入,<aioutput>代表你的输出。
<userinput>帮我查询下2025年2月9日的流量总数</userinput>
<aioutput>select * from flowinfo where day == 20250209</aioutput>
用户要求是:(此处是变量,引用用户输入)HTTP 请求API接口:主要是将sql语句发送到第三方系统API接口进行查询并收集返回数据。如下:
LLM分析API返回数据:如果数据过多则返回信号1,如果数据不多则返回信号0,主要还是通过提示词让大模型判断数据量大小。(当然这里也可以使用程序判断的,只是懒得写那个程序。)
LLM处理数据自然表达:主要是通过提示词将少量的数据进行友好的输出:
代码执行格式化输出数据:接口返回的Json数据进行转换,转成人类能够阅读的数据。
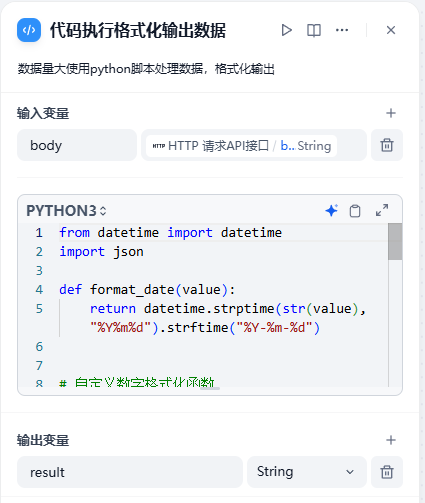
代码如下:
from datetime import datetime
import json
def format_date(value):
return datetime.strptime(str(value), "%Y%m%d").strftime("%Y-%m-%d")
# 自定义数字格式化函数
def format_number(value):
return "{:,}".format(value)
def main(body: str) -> dict:
formatted_data = []
data = json.loads(body)
for record in data:
record["day"] = format_date(record["day"])
record["allflow"] = format_number(record["allflow"])
formatted_data.append(
f"日期: {record['day']}\n流量总数: {record['allflow']}\n{'-' * 30}"
)
# 返回格式化后的数据
result = "\n".join(formatted_data)
return {"result": result}通过以上步骤基本完成了Dify和第三方系统对接,本方案采用如下流程:
- 用户输入查询需求
- LLM解析用户意图,生成SQL语句
- 调用API接口查询数据库
- LLM判断数据量大小
- 根据数据量选择不同的输出方式:
- 数据量大(>8条): 直接格式化输出
- 数据量小(≤8条): LLM优化输出
该方案结合了Dify平台的低代码优势、AI大模型的智能分析能力,以及传统数据库的高效查询能力,实现了灵活、高效且友好的数据查询与输出。
最终,这一模式不仅优化了数据查询的交互方式,同时确保了系统的稳定性和扩展性,为企业级智能数据查询与分析提供了一种可行的落地方案。